
Your Robot Is Fine. Your Data Infrastructure Isn't
The bug that doesn't look like a bug - until you've lost six months, and the unglamorous work which determines whether your robot ships.

After spending 5 years building foundational models for autonomous driving at Minus Zero, I learnt all this a hard way - because this was never the coolest thing to talk about.
Ask a senior engineer at Waymo, Tesla, or any Physical AI startup how they actually spend their time. The answer never matches the conference talks.
Control algorithms, perception architectures, planning systems - these are what get written about, presented, and funded. They’re maybe 15–20% of where engineering hours actually go. The rest disappears into data collection, labeling pipelines, dataset versioning, calibration tracking, validation scripts, evaluation infrastructure, and debugging corruptions that produce no error messages whatsoever.
Nobody talks about this at NeurIPS. It’s not glamorous. But it’s where the work is.
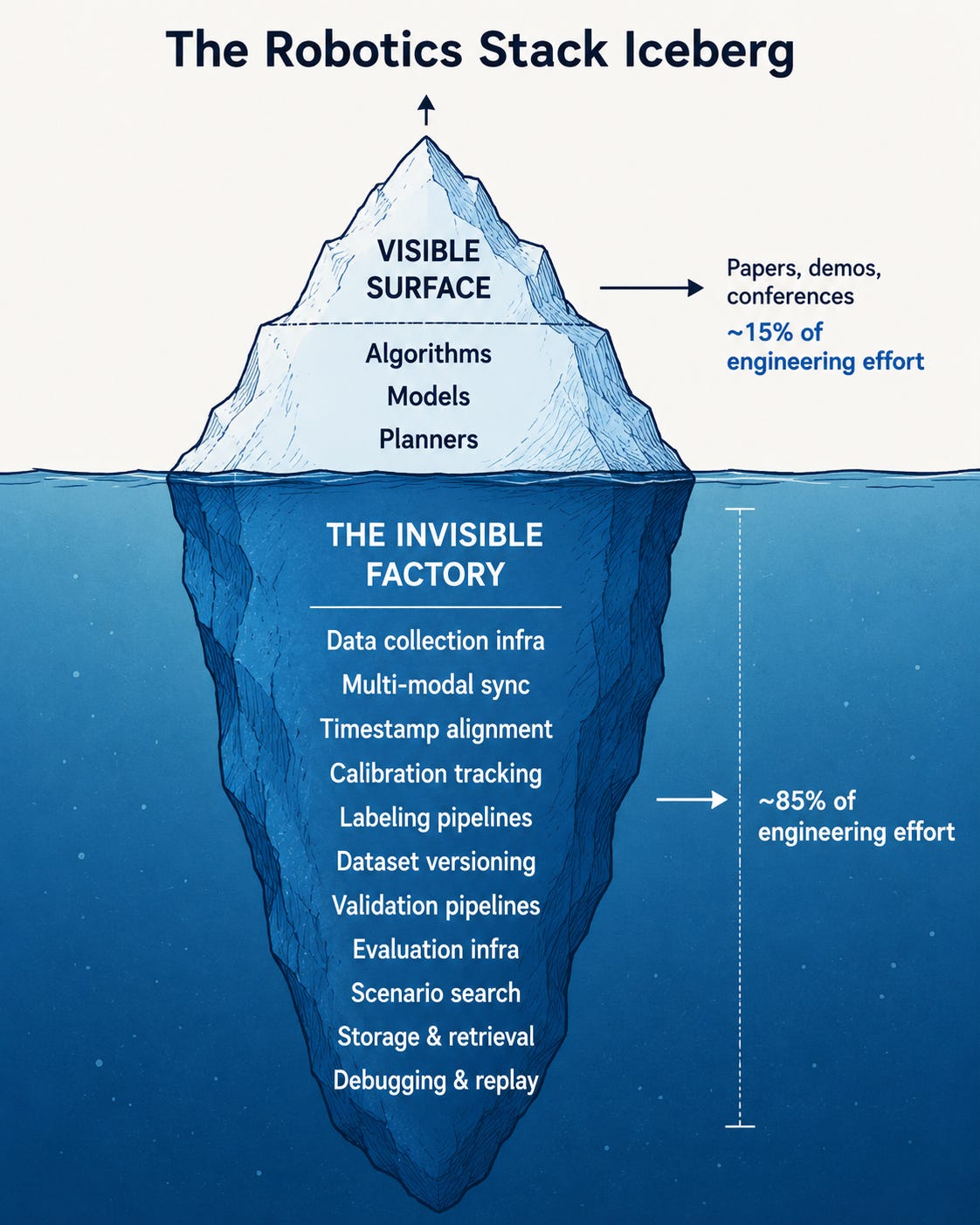
How complicated it can be?
To appreciate the hidden complexity, follow a single camera frame from capture to its eventual use in a training run six months later.
(If you already know this, feel free to skip to the next section : ) )
═══════════════════════════════════════════════════════════════
PHYSICAL LAYER
═══════════════════════════════════════════════════════════════
1. Image sensor captures photons (1/30 second exposure)
2. Image Signal Processor: demosaicing, white balance, noise reduction
3. Hardware timestamp generated by camera's internal oscillator
⚠ NOTE: This clock is NOT the system clock. It drifts 1–5ppm.
4. Frame transmitted over GigE Vision to compute unit
5. OS receives frame, applies software timestamp
⚠ NOTE: This is a SECOND timestamp. The two will diverge.
6. DMA copy into shared memory ring buffer
MIDDLEWARE LAYER
═══════════════════════════════════════════════════════════════
7. ROS 2 node reads frame, wraps in sensor_msgs/Image
8. Publishes to /camera/front_left/image_raw (~1MB per frame)
9. Subscribers: perception node, recorder node, visualization node
10. Three independent subscribers receive the same message.
⚠ Each applies processing with unknown latency jitter.
RECORDING LAYER
═══════════════════════════════════════════════════════════════
11. Recorder serializes to MCAP format with LZ4 compression
12. Writes to local NVMe in 30-second segments
13. Session metadata: robot_id, session_id, operator, timestamp range
14. Segment complete → MD5 checksum computed on in-memory buffer
⚠ NOTE: If the NVMe has a bad sector, the write is "successful"
but the data is corrupted. The checksum passes.
15. Segment pushed to upload queue
SENSOR FUSION ASSOCIATION
═══════════════════════════════════════════════════════════════
16. LiDAR arriving at 10Hz (different oscillator, different clock)
17. IMU at 200Hz (yet another clock)
18. GPS at 10Hz (UTC-synchronized via PPS signal — most accurate)
19. To fuse: what was the robot's pose at this exact camera timestamp?
⚠ Requires sub-10ms alignment. Uncompensated drift → wrong geometry.
20. Calibration lookup: where is this camera relative to LiDAR?
⚠ Is the calibration from this session? Or last week's? Did it drift?
⚠ Calibration changes with temperature. No one tracked today's temp.
UPLOAD AND INGEST
═══════════════════════════════════════════════════════════════
21. Upload to object storage via chunked multipart upload
22. Upload job written to message queue (Kafka / SQS)
23. Ingest service parses MCAP, extracts metadata
24. Frame indexed: timestamp_ns, robot_id, session_id,
scenario_type, GPS_bbox, weather_tag, calibration_id
⚠ NOTE: "weather_tag" was added to the schema in month 4.
⚠ All frames before month 4 have NULL weather_tag.
⚠ Training code does not handle NULL. Silent filter removes 40%
⚠ of your data and you don't notice.
VALIDATION PIPELINE
═══════════════════════════════════════════════════════════════
25. Timestamp monotonicity check [PASS]
26. Frame drop detection (>1% gap rate) [PASS]
27. Calibration validity check [FAIL — 3 frames]
⚠ Clock stutter caused those 3 frames to fall outside
⚠ the calibration validity window. Flagged for review.
28. Brightness range check [PASS]
29. Compression integrity check [PASS — does not catch
⚠ bad-sector corruption, because checksum was wrong]
LABELING
═══════════════════════════════════════════════════════════════
30. Frame sampled for annotation (diversity heuristics)
31. Sent to annotation pipeline: objects, lanes, drivable area
32. Human annotation: ~8 minutes per frame
33. QA review by senior annotator
34. Labels written to database with annotator_id, QA_status
35. Labels joined to frame via (robot_id, timestamp_ns)
⚠ NOTE: Labeling team changed in month 6.
⚠ New team uses slightly different bounding box convention.
⚠ Mixed conventions now exist in the training set.
DATASET VERSIONING
═══════════════════════════════════════════════════════════════
36. Frame added to dataset v3.7.2 manifest
37. Train/val/test split assigned
⚠ Split is by session_id, not frame. Mostly prevents leakage.
⚠ But the robot drove the same route twice in different sessions.
⚠ Similar frames appear in both train and test.
38. Dataset committed to DVC remote with git hash
TRAINING
═══════════════════════════════════════════════════════════════
39. Training job: 64 A100s, dataset v3.7.2
40. Frame decoded, augmented, normalized
41. Forward pass. Gradient. Weight update.
⚠ The bad-sector-corrupted frame was included.
⚠ So were the frames with wrong bounding box convention.
⚠ So were the test-set-leaked frames.
⚠ The model trains successfully.
EVALUATION AND REGRESSION
═══════════════════════════════════════════════════════════════
42. mAP computed per class, per condition
43. Regression detected: pedestrian mAP dropped 2.3% in construction zones
44. Root cause hunt: Is it the model? The data? A labeling issue?
⚠ Debugging this takes 3 engineer-weeks.
⚠ The answer: bad-sector corruption + mixed bounding box convention
⚠ + 40% data loss from NULL weather_tag filter.
⚠ None of these produced a single error message.
SIX MONTHS LATER
═══════════════════════════════════════════════════════════════
45. Engineer queries data lake for construction zone, night, rain frames
46. Returns 8,000 results
47. 340 have corrupted calibration (calibration service bug in month 2)
48. 200 have labels from deprecated tool with different class definitions
49. Engineer spends 3 days reconstructing which frames are usable
50. Eventual usable frames: ~7,460 of 8,000 — but which 7,460?
⚠ No provenance trail. Must re-validate manually.
═══════════════════════════════════════════════════════════════
TOTAL TIME FROM CAPTURE TO USABLE TRAINING EXAMPLE: 6 months.
TOTAL ENGINEERING-DAYS LOST TO DATA ISSUES: ~20.
TOTAL ERROR MESSAGES PRODUCED BY ANY OF THESE ISSUES: 0.
═══════════════════════════════════════════════════════════════
This isn’t a pathological story. This is Tuesday at a typical robotics startup.
So what poses as a problem?
These are the data problems that don’t produce stack traces. They produce models that fail in production in ways that take months to diagnose.
Timestamp Drift - Camera hardware oscillators drift by 1–5 parts per million. After a 4-hour collection session, a sensor running at 2ppm drift is 29ms off from the system clock. During sensor fusion, your perception stack associates a LiDAR point cloud (captured at time T) with a camera frame (nominally at T, actually at T+29ms). At highway speeds (30 m/s), 29ms represents 87 centimeters of vehicle motion. You are training your model with a point cloud that doesn’t correspond to the image it thinks it does. This doesn’t crash anything. It silently corrupts your 3D bounding box training data, slightly but persistently - across every hour of data collected with that sensor.
Schema Drift - You add a field to your custom protobuf message definition. You’re careful: it’s an optional field, backward compatible. But your MCAP recording tool hashes the message schema to identify the message type. Old bags reference the old hash. Your replay tool, written for the new schema, can’t find the message definition for the old hash. Three months of bags are now unreadable without a migration script. The migration script takes two weeks to write and test properly. During those two weeks, you discover that 4% of your bags also have a related issue with the companion metadata schema.
Silent Disk Corruption - A frame is written to disk. The NVMe drive has a developing bad sector. The OS reports the write as successful. The checksum was computed on the in-memory buffer before the write. The corrupted frame sits on disk, looking exactly like a valid image, producing subtle artifacts that a labeler annotates as object detections. You’ve injected structured noise into your training set.
Benchmark Leakage - Your evaluation set is sampled from the same routes as your training set, just at different timestamps. A rare sign type appears in both training and evaluation because you drove past it every morning during data collection. Your per-class mAP on that sign type looks excellent. Your production system fails at a different intersection with the same sign type, because it memorized the specific instance rather than the class.
Calibration Drift - Camera intrinsics shift with temperature. LiDAR-camera extrinsic calibration can change after a minor collision that leaves no visible damage. If calibration is recorded once weekly, every datum collected between calibration sessions is tagged with potentially incorrect geometry. Models trained on this data learn the wrong spatial relationships - consistently, invisibly.
Label Inconsistency - Labeling vendor A annotates occluded pedestrians with a
partially_visibleflag. Labeling vendor B, hired when the first vendor couldn’t scale, annotates only fully visible pedestrians. You merge their outputs without reconciling the conventions. Your model now receives the same visual stimulus with different ground truth depending on which batch the frame came from. You’ve permanently injected irreducible label noise.Duplicate Data - A recorder bug causes 2% of sessions to be written twice under different session IDs. Your training set contains tens of thousands of effectively duplicated frames. The model overfits to these examples. Evaluation performance looks inflated - the test set also contains duplicates. The effect is invisible until you deploy to a new environment and the model catastrophically fails on distributions it’s never actually generalized to.
None of these produce error messages. They produce models with mysterious behavior, regressions that can’t be explained, and debugging sessions that last months.
Physical AI is in its Pre-Git Era
Consider where software engineering was in 1990. Code on network drives. No version history. “Works on my machine” was an acceptable bug report. Reproducing a build meant manually reconstructing the environment. Merging two developers’ work meant emailing patches.
That’s where robotics data is today.
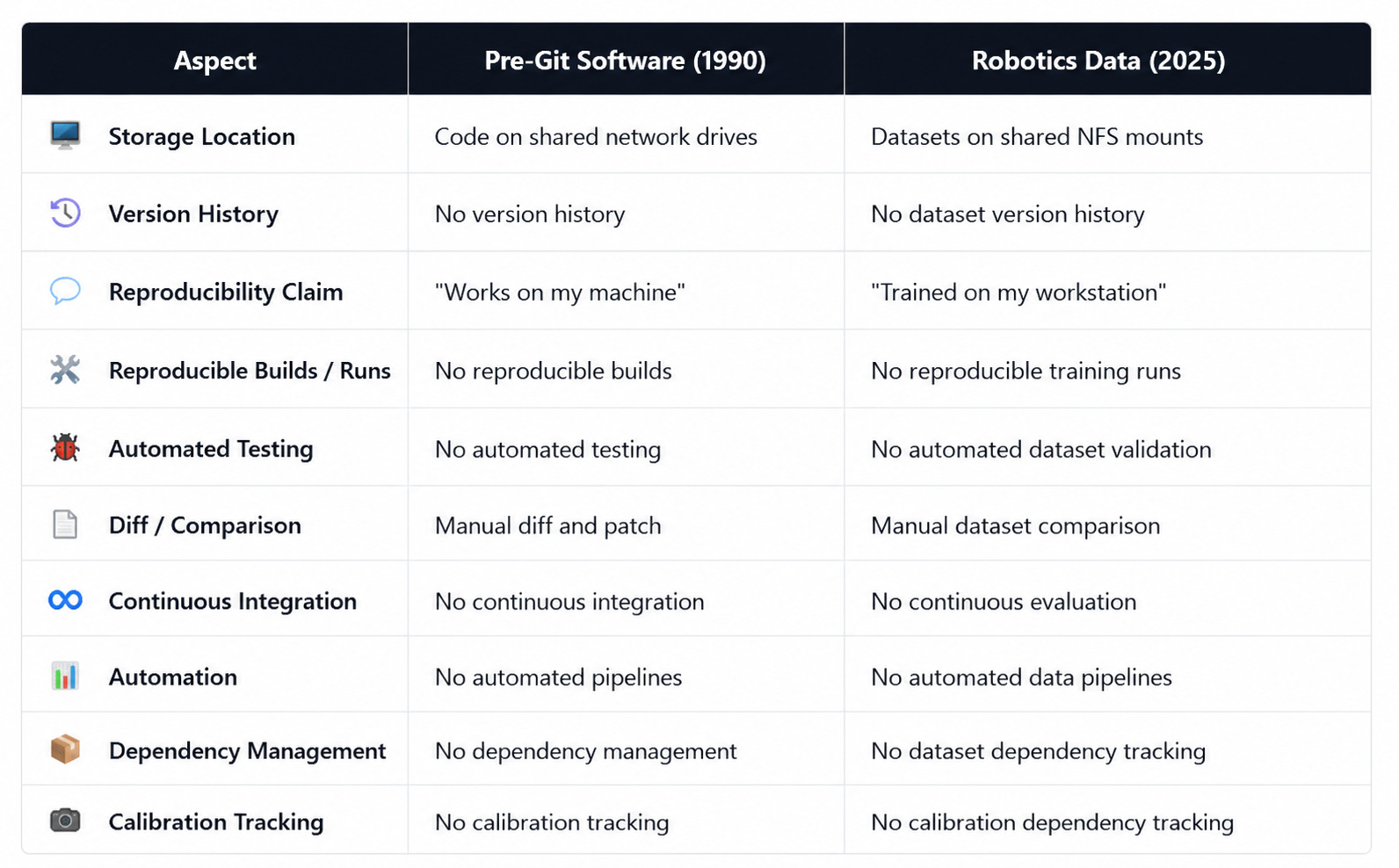
Datasets live on shared NFS mounts without versioning. There’s no history of which data produced which model. Training runs aren’t reproducible because no one tracked which files were actually used. “The model trained on my workstation” is common. Merging two teams’ datasets means copying files and hoping for no conflicts.
The ML world partially solved this for static image data. Weights & Biases tracks experiments. DVC versions datasets. Hugging Face hosts models. But these tools were built for static datasets of labeled images or tabular rows. They don’t understand time-synchronized multi-modal sensor streams, calibration dependencies, coordinate frame transforms, or the need to replay a scenario to debug a failure. They’re the right shape of solution applied to the wrong problem structure.
Robotics needs purpose-built tooling. Not a reskin of MLflow. Something designed around what embodied physical data actually is.
MCAP - developed by Foxglove, now the default format in ROS 2 - is a good start: self-contained, corruption-resistant, schema-embedded, multi-language. But MCAP solves the storage format. It doesn’t solve versioning, provenance, calibration tracking, scenario search, or continuous evaluation. We have one good brick. The building doesn’t exist yet.
Why Foundation Models Make This Worse?
There’s a seductive belief that as models scale and become more capable, messy data becomes less of a problem - the model will figure it out. This is exactly backwards.
Physical Intelligence’s π0 is trained on data from seven different robot hardware platforms, across eight task types, mixed with internet-scale vision-language pretraining. The hard work isn’t the architecture - π0 builds on existing VLM foundations. The hard work is making data coherent across robot morphologies with different action spaces, different observation definitions, and different physical constraints. That is not a modeling problem. It is a data harmonization problem that precedes any modeling work.
Waymo’s recent scaling law research puts a sharper point on it. Their finding: for autonomous driving tasks, unlike language models, optimal systems tend to be “relatively smaller in size, while requiring significantly more data to train.” More data is the path to better systems - which means more data collection, more data operations, and more quality control, not less.
Scaling model capacity without scaling data infrastructure doesn’t plateau gracefully. It fails in ways that look like training instability, unexplained regressions, or evaluation results that don’t transfer to production. The root cause is usually in the data. The debugging path is usually weeks long.
What the Leaders Actually Built?
Tesla’s data engine - described by Andrej Karpathy at multiple public presentations - is the clearest public acknowledgment that data infrastructure, not model architecture, is the core competitive advantage in autonomous systems.
Trigger classifiers run on the production fleet, detecting situations where the current model and a candidate model diverge, or where the model’s output conflicts with the driver’s behavior. Those triggers route specific clips for annotation and retraining. New models run silently on production vehicles in “shadow mode” - outputs compared against the production model, never actually controlling the car. This is a continuous evaluation system running at fleet scale across millions of vehicles. At AI Day 2022, Tesla described datasets on the order of 1.5 petabytes for training their occupancy network alone.
None of that is model architecture. All of it is data infrastructure.
Waymo maintains 500,000+ hours of driving data. New software release candidates are automatically evaluated against millions of simulated miles. Their simulation system generates scenarios from real-world logs - which requires log management, scenario indexing, and closed-loop evaluation infrastructure of considerable sophistication. Dedicated teams work on sensor simulation, scenario search, and evaluation tooling. Not just perception and planning.
Karpathy, at a CVPR workshop, made it plain: “The only sure certain way I have seen of making progress on any task is, you curate the dataset that is clean and varied and you grow it and you pay the labeling cost.”
The algorithm is almost secondary. The machine that creates and validates training data is the real product. The robotics organizations that have achieved meaningful scale haven’t done it primarily through algorithmic novelty. They’ve done it by building industrial-grade data operations.
So how does it affect a typical robotics startup trajectory?
Months 1–3: The robot moves. The demo works. The team is energized.
Months 4–6: A model trains. It works in the lab. Investors are interested.
Months 7–9: Real-world deployment. Performance degrades. Debug manually. Fix cases individually.
Months 10–12: Retrain the model with new data. Performance is worse than before. The team doesn’t know why.
Months 13–18: A senior engineer joins. She discovers: no dataset versioning, no reproducible training, evaluation set contaminated with training data, calibration not tracked, labeling conventions inconsistent across vendors. Six months of reconstruction work begins.
The reason founders underestimate data operations is that early success doesn’t require them. Two engineers can build a demo that impresses investors with zero data infrastructure. The failure modes only surface when you need to reproduce a training run, when a calibration change corrupts months of data you didn’t know was invalid, or when your evaluation set has silently leaked into your training set and you’ve been measuring the wrong thing for half a year.
The first dedicated data infrastructure engineer - someone who designs the schema before you have data, builds the validation pipeline before you have regressions, creates the reproducible evaluation framework before you establish a baseline - often has more total leverage than the third ML researcher. The ML researcher improves the current model. The infrastructure engineer makes all future models improvable faster. The second is harder to justify to a board. It’s more important.
But if we do X then it’s not a problem?
“Simulation solves the data problem.”
Simulation reduces the need for some real-world data collection. It doesn’t eliminate the data problem - it adds a parallel one. Simulation asset management requires versioning. Domain randomization parameters require tracking. Sim-to-real gap requires characterization against real-world benchmarks. Synthetic data generation pipelines fail in ways that look exactly like real data pipeline failures: schema drift, coverage gaps, distribution mismatch, evaluation leakage. Waymo runs millions of simulated miles per software release candidate. That infrastructure - scenario management, parameter tracking, results storage, regression detection - is a data operations problem of comparable complexity to the real-data problem.
“Foundation models trained on internet data will generalize to robotics.”
Internet-scale pretraining provides genuine value for visual recognition and language grounding. It doesn’t help with calibration tracking, multi-modal timestamp synchronization, or the physical geometry of sensor fusion. The “last mile” of embodied AI - grounding general knowledge in precise physical sensor data - requires exactly the infrastructure this article describes. Physical Intelligence’s π0, which makes aggressive use of VLM pretraining, still required building a multi-robot data collection and harmonization infrastructure as the core technical work.
“This is just MLOps with extra steps.”
MLOps tools were designed for static datasets. Robotics data is time-synchronized, calibration-dependent, multi-modal, spatially grounded, and replay-dependent. Applying MLflow to manage a dataset that includes MCAP files with associated per-session calibration metadata, LiDAR-camera extrinsics, GPS trajectories, and scenario tags reveals immediately that the abstractions don’t transfer. The tooling gap is real and purpose-built solutions are needed.
“Big companies have this problem. Startups should focus on shipping product.”
This is precisely backwards. Big companies can absorb three months of debugging a data corruption issue. Startups cannot. The startup that establishes data discipline in months 1–3 compounds its learning rate for the entire subsequent trajectory. The one that defers it will spend months 12–18 in reconstruction mode while competitors iterate. Early investment in data infrastructure is not a distraction from building the product - it is the infrastructure on which the product’s learning rate depends.
“Better sensors and hardware will reduce calibration and sync problems.”
Better hardware reduces but doesn’t eliminate calibration drift. More importantly, tracking calibration state over time - associating every data frame with the calibration that was valid at that moment, flagging data when calibration may have changed, managing calibration as a versioned artifact - is not a sensor problem. It’s a data management problem. Even perfect sensors require a calibration management system.
How should we solve it?
DevOps emerged when shipping code without operational discipline stopped scaling. MLOps emerged when deploying models without infrastructure discipline stopped scaling. RobotOps is next - and the path is legible.
It all starts with changing how we approach a robotics problem - and try giving a serious thought through the ‘DevOps for Robotics’ perspective.

Standardize before you tool up. MCAP is a good start, but the next step is a robotics dataset format analogous to Parquet - purpose-built for time-synchronized multi-modal sensor data, with versioning and calibration baked in. The community needs to converge on this before every company keeps reinventing it privately. At the team level, this means defining canonical sensor schemas, a timestamp policy (hardware timestamps only, sync mechanism documented), calibration tracking (every file references a calibration session ID with a validity window), and a session metadata standard - written down before you have data. Two weeks of work that saves six months.
Build the platform layer, not five duct-taped tools. Early entrants - Foxglove, Rerun, Scale AI, HuggingFace via LeRobot - are solving pieces of the puzzle. The gap is integration: schema management, calibration tracking, dataset lineage, and scenario search in one coherent platform.
Treat data like code: validate, checksum, test. Every model commit should automatically validate datasets, check timestamp and calibration integrity, run scenario regression benchmarks, and compare against historical results - the same discipline software teams built into CI/CD two decades ago. In practice, this starts small: checksum every recorded file in-memory before upload and verify after (one engineering-day, catches silent corruption before it reaches training), and run a validation script before every training job - timestamp monotonicity, frame drop rate, calibration validity, label schema compliance, duplicate detection. Fail loudly, automatically.
Make scenario search the primary interface. Manual log inspection should be as archaic as grepping server logs. The target: query petabyte-scale sensor archives the way you’d query a database - by scenario type, condition, failure mode, time window. The scenario library becomes more valuable than any individual model checkpoint. Build your evaluation set first as part of this discipline: sample deliberately, freeze it, version it, never train on it, and store every result against it with model version, dataset version, and timestamp.
Formalize the discipline and hire for it. Robot Data Engineer needs to be a real job title with a real career path, not a responsibility absorbed by whoever has bandwidth. Counterintuitively, the first data infrastructure hire often has more leverage than the third ML engineer - and is the recommendation most consistently ignored despite having the highest ROI.
A better model architecture can be published and reproduced in six months. A decade of well-organized operational data cannot.
References and Resources
Foundational Papers
Open X-Embodiment Collaboration (2024). Open X-Embodiment: Robotic Learning Datasets and RT-X Models.ICRA 2024. https://robotics-transformer-x.github.io/
Black et al. (Physical Intelligence, 2024). π0: A Vision-Language-Action Flow Model for General Robot Control.https://physicalintelligence.company/download/pi0.pdf
Brohan et al. (Google, 2022). RT-1: Robotics Transformer for Real-World Control at Scale. arXiv:2212.06817
Chi et al. (TRI / Columbia, 2023). Diffusion Policy: Visuomotor Policy Learning via Action Diffusion.arXiv:2303.04137
Sun et al. (Waymo, 2020). Scalability in Perception for Autonomous Driving: Waymo Open Dataset. CVPR 2020.
Waymo (2026). Scaling Laws Research: Data-Driven Autonomous Driving.https://datacenterdynamics.com/en/news/waymo-research-confirms-self-driving-scaling-laws/
Engineering Blogs and Talks
Karpathy, A. (Tesla Autonomy Day, 2019). Tesla Data Engine.
Karpathy, A. (Tesla AI Day, 2021). Autopilot and Auto-Labeling.
Karpathy, A. (CVPR 2021 Workshop on Autonomous Driving). Lessons learned from deploying neural networks at Tesla.
Waymo Engineering. Industry Best Practices in Robotics Software Engineering. arXiv:2212.04877
Foxglove Blog. Introducing the MCAP File Format. https://foxglove.dev/blog/introducing-the-mcap-file-format
Rerun Blog. Introducing Experimental MCAP Support. https://rerun.io/blog/introducing-experimental-support-for-mcap-file-format
Segments.ai. MCAP vs ROS bag: Simplifying Multi-Modal Sensor Data. https://segments.ai/blog/mcap-vs-ros-bag-simplifying-multi-modal-sensor-data-in-robotics/
Community and Discussion
ROS Discourse: https://discourse.ros.org/ (Active community discussions on data management, MCAP, and tooling evolution)
Papers With Code — Robot Learning: https://paperswithcode.com/task/robot-learning
ScenarioNet (open-source scenario management): arXiv:2306.12241
Technical claims in this article about engineering time allocation represent informed analysis based on public statements from industry engineers, published engineering blogs, and the author’s experience in Physical AI development. Where specific figures are cited (e.g., Waymo’s 500,000 hours of driving data, Tesla’s 1.5PB dataset scale), sources are linked above. Claims presented as analysis are clearly identified as such.
The argument that data infrastructure determines competitive outcomes in Physical AI is not a prediction about the future. It is an observation about the present, backed by every major organization that has achieved meaningful scale in autonomous systems.